The Evolution of Flink at Simpl

Real-Time Processing at Simpl
At Simpl, we offer a variety of innovative payment solutions, including options like "Pay in 3" and "Pay Later." To ensure a seamless customer experience, our platform operates with minimal latency, enabling real-time data processing. This is critical to delivering a safe, efficient, and engaging user experience. Key use cases that benefit from real-time processing at Simpl include:
- Fraud Detection
- Real-time Transaction Monitoring
- Credit Limit Enhancement
Why Flink?
At Simpl, we utilize machine learning (ML) models for several critical use cases, such as fraud detection and credit limit upgrades. Traditionally, these models relied on historical data, which caused delays in generating results. To enhance both the speed and accuracy of our predictions, we aimed to transition to real-time execution.
The primary challenge was moving from a batch processing model, where data was analyzed once a day, to a real-time architecture. This shift would enable us to detect and respond to use cases as they occur, improving our ability to act on emerging trends and anomalies.
The solution? Empowering our ML models to process incoming events in real-time, triggering actions immediately as events unfold.
To achieve this, we needed a robust framework capable of handling large volumes of streaming data and enabling instant predictions. After evaluating various options, we selected Apache Flink due to its powerful real-time stream processing capabilities.
Approaches Explored
Approach 1: Standalone Event consumer
One possible approach was to use a generic Kafka consumer (our event source) written in Python or Java and hosted as a service. However, this option comes with its own set of pros and cons.
Pros:
- Easy learning curve
- Faster implementation
Cons:
- Scalability could become an issue with high traffic, requiring the entire service to be scaled.
- When issues occur in a stream processing application, it can result in either lost or duplicated results. With a standalone consumer, we would have needed to implement the functionality to recover from such failures ourselves.
- Additionally, state management and the ability to restart on failure would have needed to be built from scratch.
Approach 2: Flink
Flink offers out-of-the-box functionality for real-time stream processing.
Pros:
- Provides parallelism at both the job and operator levels.
- Offers a wide range of built-in operators, such as window operators, joins, etc., which are essential for stream processing.
- Includes snapshot, savepoint and checkpoint capabilities, which help achieve "at least once" delivery for each event.
- Strong community support.
- Provides connectors to systems like Kafka, PostgreSQL, and more.
Cons:
- Steep learning curve.
- Requires management and maintenance of the Flink cluster.
There were some other considerations as well such as AWS Kinesis but after considering all the aspects including costs we decided to go ahead with Flink.
How we started ?
We initially set up a standalone Flink cluster on a couple of powerful on-demand EC2 machines. This cluster consisted of 1 Job Manager and 2 Task Managers. With this setup, we were able to run some of our Flink pipelines and ML models in real-time. However, while there were certain benefits, there were also some challenges with this standalone configuration.
Pros:
- Easy to deploy and add new Flink pipelines.
- Simple to scale by adding new Task Managers (EC2 instances).
Cons:
- The memory of Task Managers is shared across different Flink pipelines, leading to inefficient memory distribution.
- The cluster cannot scale automatically, requiring manual intervention to scale up or down.
Our Observations
Over time, as we added more Flink pipelines to the standalone cluster, we continued to scale by adding new Task Managers to keep the pipeline efficiency up to date. However, this approach led to several recurring issues:
- Non-uniform Memory Distribution: Since Task Managers were shared across different pipelines, the uneven distribution of memory caused frequent lags in the processing of other pipelines running on the same cluster.
- Difficulties in Upscaling Pipelines: Upscaling specific Flink pipelines became challenging because all Task slots were shared across the cluster, making it difficult to allocate resources efficiently to individual pipelines.
- Cost Increase: To scale the cluster further, we added more Task Managers (i.e., additional EC2 on-demand machines), which caused the cost to shoot up.
- Log Segregation: Logs were stored in shared locations, making it challenging to debug issues efficiently.
- Failure Isolation: Since we were using a shared standalone cluster, memory constraints sometimes caused multiple pipelines to fail simultaneously. Restarting the entire cluster was necessary to get them back online.
- Access Control: There was limited control over job initiation and cancellation, and we lacked a proper audit trail, as everything was managed from a single UI.
Optimising Our Flink Architecture
Phase 1. Downgrading Ec2 Instances
At first, we took the "throw hardware at it" approach to scale our Flink cluster. However, we quickly realized that this was both unsustainable and costly. As a result, our first priority shifted to optimizing the cost of the Flink cluster while ensuring that the resources remained suitable for the active pipelines. By using monitoring tools like Grafana, we discovered that the CPU utilization on our existing EC2 instances was relatively low. With this insight, we decided to adjust the instance types within the cluster to better match the workload.
Result: This adjustment resulted in an immediate 40% reduction in costs, with no negative impact on the performance of the pipelines.
Phase 2. Digging Into Flink Application Mode
As we anticipate significant growth in traffic, we realized that even after updating our instance types, adding new pipelines would still require provisioning additional EC2 instances. This approach, while effective for the short term, wouldn't fully address our future scaling needs or memory management challenges, and would likely lead to escalating costs as we expand. To position ourselves for future scale, we decided to move away from the standalone cluster setup and transition to Flink Application Mode. This transition enables us to better handle scaling, optimize resource usage, and effectively manage increased traffic as we grow.
2.1 Setup for Flink Application Mode
Once we decided to transition to Application mode, the next challenge was determining the best way to set it up. We had two primary options to consider:
- Option 1: Flink on EC2 Instances
- Setup: Requires running multiple Flink clusters, each dedicated to a single pipeline, similar to a standalone setup.
- Scalability: To scale, new EC2 instances would need to be provisioned for each additional pipeline, leading to potential challenges in resource allocation and management.
- Cost: This approach can become costly as more instances are added, especially if memory is not efficiently distributed across pipelines.
- Management: Manual management of clusters, including scaling, memory allocation, and fault tolerance, would be necessary.
- Flexibility: Offers more control over individual resources but lacks the automation and orchestration benefits of Kubernetes.
- Option 2: Flink on Kubernetes
- Setup: Leverages the Flink Kubernetes Operator to run Flink in application mode on a Kubernetes cluster, enabling more streamlined management of pipelines.
- Scalability: Kubernetes allows for dynamic scaling, making it easier to handle increased traffic and additional pipelines without manually provisioning new instances.
- Cost: Can be more cost-efficient due to automated resource allocation and better utilization of underlying infrastructure.
- Management: Kubernetes simplifies cluster management, offering built-in tools for scaling, fault tolerance, and resource distribution.
- Flexibility: Offers more flexibility in terms of deployment, scaling, and managing pipelines in a unified environment, with less manual intervention.
After evaluating the two options, we chose to proceed with the Kubernetes setup for Flink. This decision was driven by Kubernetes' ability to offer better scalability, cost-efficiency, and simplified management. With Kubernetes' automation and built-in scaling tools, it aligned with our long-term goals of efficiently handling growing traffic and increasing pipelines while minimizing manual intervention.
2.2 Cost Management with AWS Spot Instances
Since we opted to run separate Flink clusters (Application Mode) for each pipeline on Kubernetes, the cost could have escalated significantly if we relied solely on on-demand machines for the underlying infrastructure. To address this, we utilized AWS Spot Instances within the Kubernetes cluster. While Spot Instances are more powerful (if the cluster with spot instance pool is chosen correctly), they are considerably cheaper than on-demand instances due to AWS's pricing model. By combining Spot Instances with Kubernetes' dynamic scaling capabilities, we were able to maintain cost efficiency while effectively scaling our infrastructure to support multiple Flink pipelines.
Phase 3: Solution Rollouts
3.1 Development
To make our Flink code compatible for deployment in Application Mode, we had to implement several changes across all our pipelines. We started with one pipeline as a proof of concept (POC). The required changes included:
- Dependency Updates: We updated the Flink version along with related dependencies, such as the Kafka connector, initially upgrading to Flink 1.17.
- Dockerization: We containerized the Flink pipeline to ensure it could run seamlessly in a Kubernetes environment.
- Flink Deployment Configuration: We created a Flink deployment file compatible with the Flink Kubernetes Operator to facilitate easy deployment and scaling.
Minimal example:

3.2 Infra setup
To run Flink on Kubernetes using the Kubernetes operator, the first step was setting up the Kubernetes cluster, which proved to be a tricky task. The challenges included:
- Choosing a Mixed Pool of AWS Spot Instances: We carefully selected a mix of Spot Instances to balance cost efficiency and performance, ensuring optimal resource allocation for our workloads.
- Access Control Configuration: Proper access control was crucial to maintain security and efficient resource management across the Kubernetes cluster.
- Networking Setup: We configured networking to enable secure access to databases and services, ensuring smooth communication within the infrastructure.
- Deploying the Flink Kubernetes Operator: The Flink Kubernetes operator was deployed to effectively manage Flink clusters, enabling seamless deployment in application mode.
- Implementing Auto-Scaling for the Kubernetes Cluster: To manage fluctuating workloads, we integrated auto-scaling capabilities into our Kubernetes cluster using Karpenter. This dynamically adjusts resource allocation based on demand. Karpenter automatically selects and scales AWS Spot instances, prioritizing instance types with 8, 16, or 32 CPUs from the c and m families (e.g., c5.2xlarge, m5.4xlarge). It ensures instances are Linux-based, x86_64 architecture, and third-generation or newer. Additionally, it consolidates underutilized nodes and replaces nodes older than 7 days, optimizing both cost and cluster health.
3.3 Challenges Encountered

Introducing changes is like getting a new pet – cute and exciting at first, but there are a few messes to clean up before everything settles down! We had our own set of challenges along the way.
Since we were running Kubernetes on Spot instances, there's always the risk that AWS could reclaim them at any time. This means that any pod, including our Flink pipeline, could suddenly be shut down. Luckily, the Kubernetes Flink operator helped us automatically revive the pipeline without manual intervention, so we didn't need to worry about the pipeline going down indefinitely. However, there were occasions when the pipeline kept trying to restart, but couldn't due to one or many reasons.
Flink Recovery Failed: At times, when a pipeline went down and tried to recover, it failed to locate the High Availability (HA) configurations for the Flink job, resulting in the error:
Flink recovery failed org.apache.flink.kubernetes.operator.exception.RecoveryFailureException: JobManager deployment is missing and HA data is not available to make stateful upgrades.
Fix: This issue occurred due to a version mismatch between the Flink Kubernetes operator and the Flink deployment itself. To resolve this, we updated the Flink deployment to the latest version, aligning it with the operator version.
Timeout Exception: One frequent error we encountered indicated that the cluster couldn't establish a connection with the TaskManager within the allotted time frame.
java.util.concurrent.TimeoutException: Heartbeat of TaskManager with...Fix: We adjusted the timeout limits in Flink’s configuration for heartbeat.timeout and akka.timeout, ensuring the Job Manager could reconnect with the Task Manager successfully.
Current State
Currently, we are running multiple Flink pipelines for various use cases, all deployed on Kubernetes using AWS Spot Instances. These pipelines are processing over 30 million events each in real-time.
This setup has multiple benefits:
- Scalability: Running Kubernetes on Spot Instances allows us to scale both the underlying Kubernetes cluster and the Flink pipelines efficiently, ensuring optimal resource utilization.
- Seamless Integration: Flink’s integration with Kubernetes enables the auto-scaling of both the Flink pipelines and the cluster itself, providing flexibility and cost efficiency while managing growing workloads.
- High Availability and Checkpointing: By leveraging High Availability (HA) and checkpointing, we can achieve fault tolerance and "at least once" delivery guarantees, enabling us to run the cluster on Spot Instances effectively.
- Reduce costs: significantly—by around 70% compared to the initial setup.
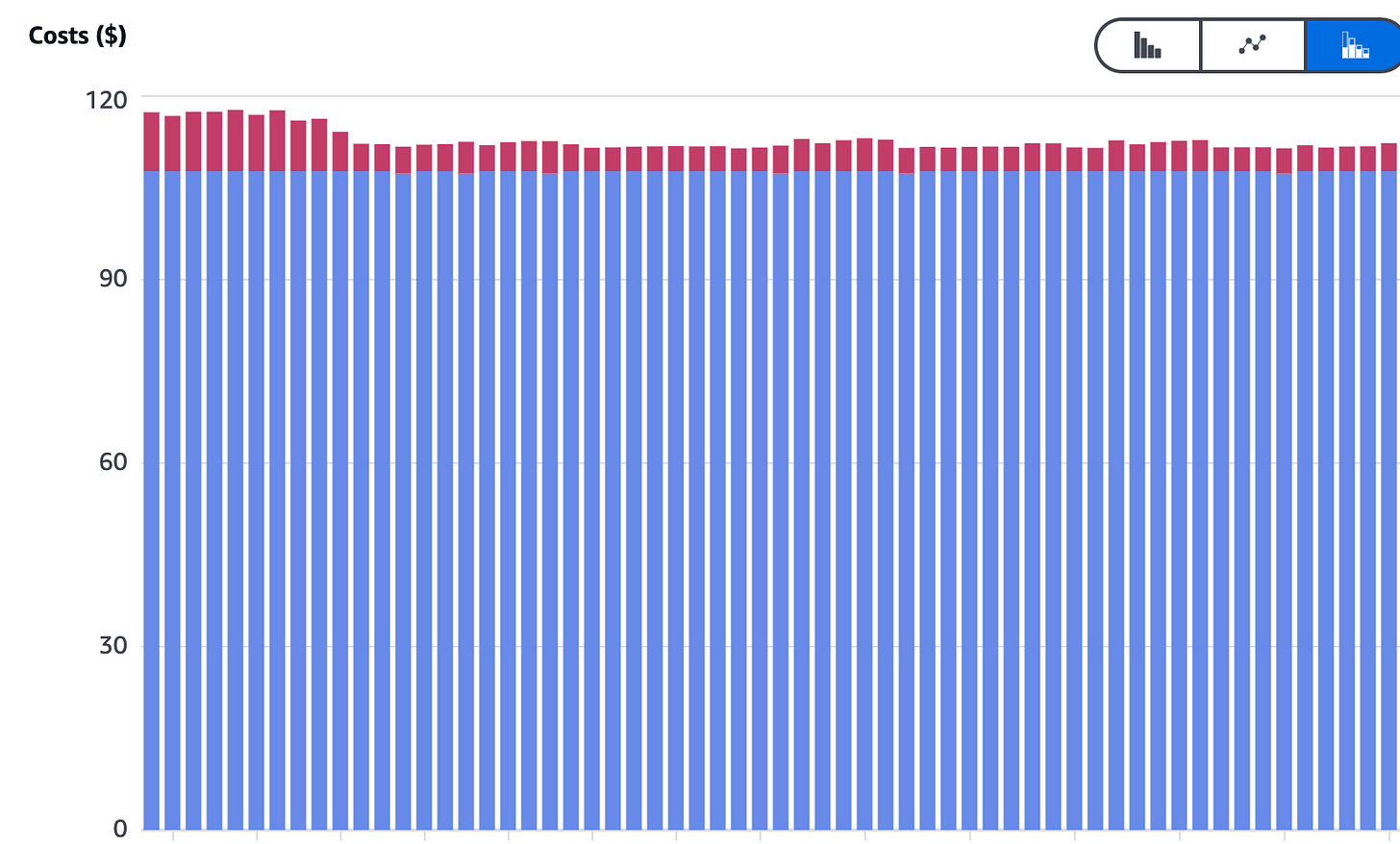
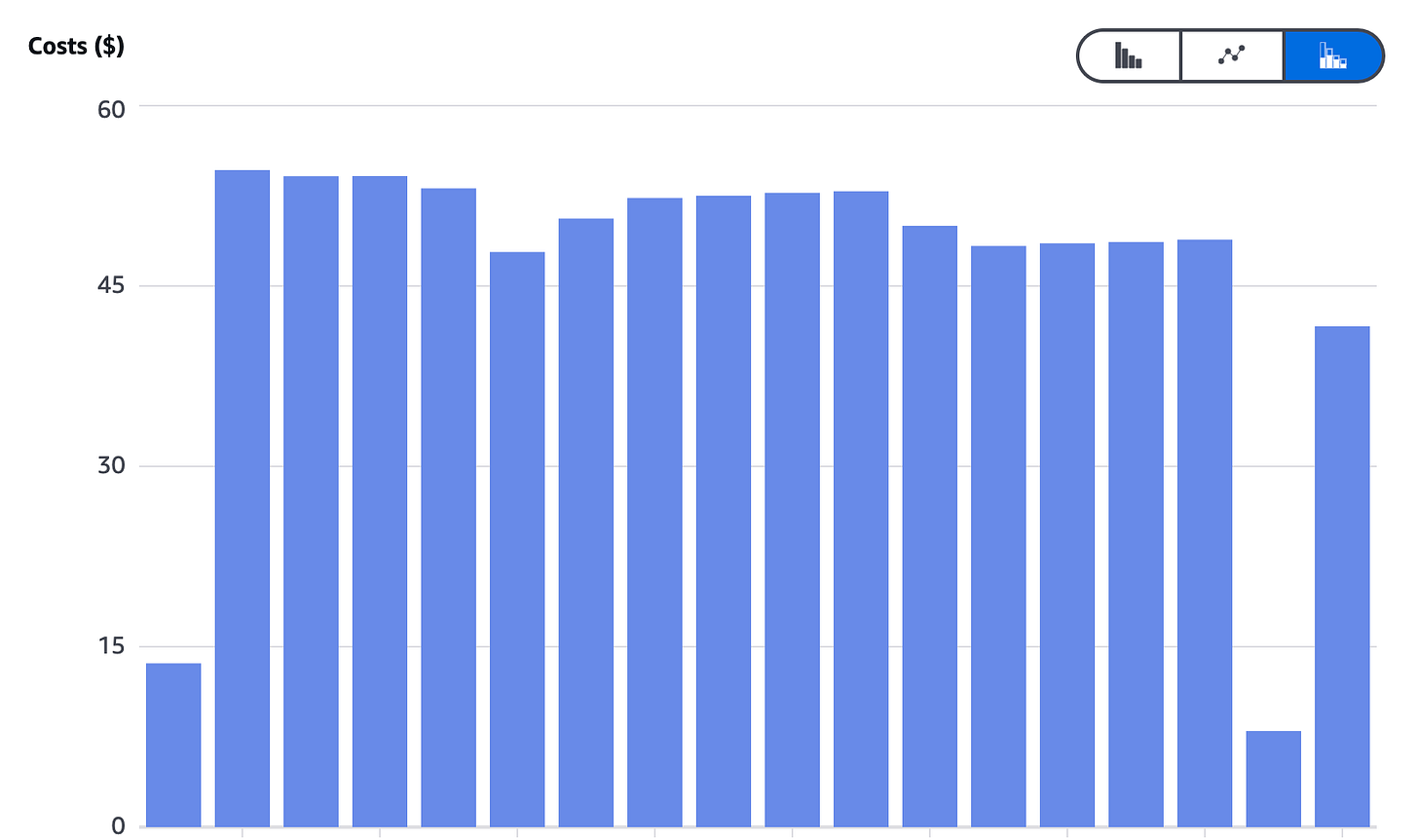
Lessons Learned
- Real-Time Processing Demands Robust Infrastructure
- Transitioning from batch processing to real-time data processing requires not just the right technology, but also a strong infrastructure. Scalable frameworks like Flink, combined with container orchestration tools such as Kubernetes, are essential to handle the volume and velocity of real-time data.
- Cost Management Is Key to Scalability
- While scaling is critical for real-time processing, it's equally important to manage costs. Leveraging AWS Spot Instances and moving to a Kubernetes-based architecture helped optimize costs significantly, making it possible to scale without compromising on performance.
- Memory Management is Crucial
- In a shared-memory environment like the standalone Flink cluster, memory management can become a bottleneck.
- Automation Reduces Operational Overhead
- Automating scaling and resource management through Kubernetes and Flink’s integrations helped us avoid manual interventions, making the system more efficient and resilient.
- Flink is a Powerful Tool, but requires Investment in Learning
- Although Flink offers tremendous benefits for stream processing, it comes with a steep learning curve. Investing time in mastering Flink's complexities pays off, but it’s essential to allocate resources for training and experimentation in the early stages.
- Continuous Monitoring is Essential
- Monitoring tools like Grafana were crucial in optimizing our infrastructure and identifying areas for improvement. Keeping an eye on CPU utilization, memory distribution, and task slot management helped us identify inefficiencies early on.
In conclusion, our journey with Flink, Kubernetes, and AWS Spot Instances has been both challenging and rewarding. By transitioning to Flink’s application mode and leveraging Kubernetes for dynamic scaling, we were able to enhance our real-time processing capabilities while cutting costs significantly.
Key lessons learned include the importance of planning, the need for continuous monitoring, and the value of adapting quickly as infrastructure scales. While the path to optimization comes with its challenges, the right tools and strategies can lead to a more efficient, flexible, and cost-effective system.
As we continue refining our setup, we look forward to tackling new challenges and further improving our data processing ecosystem. Thank you for reading!