
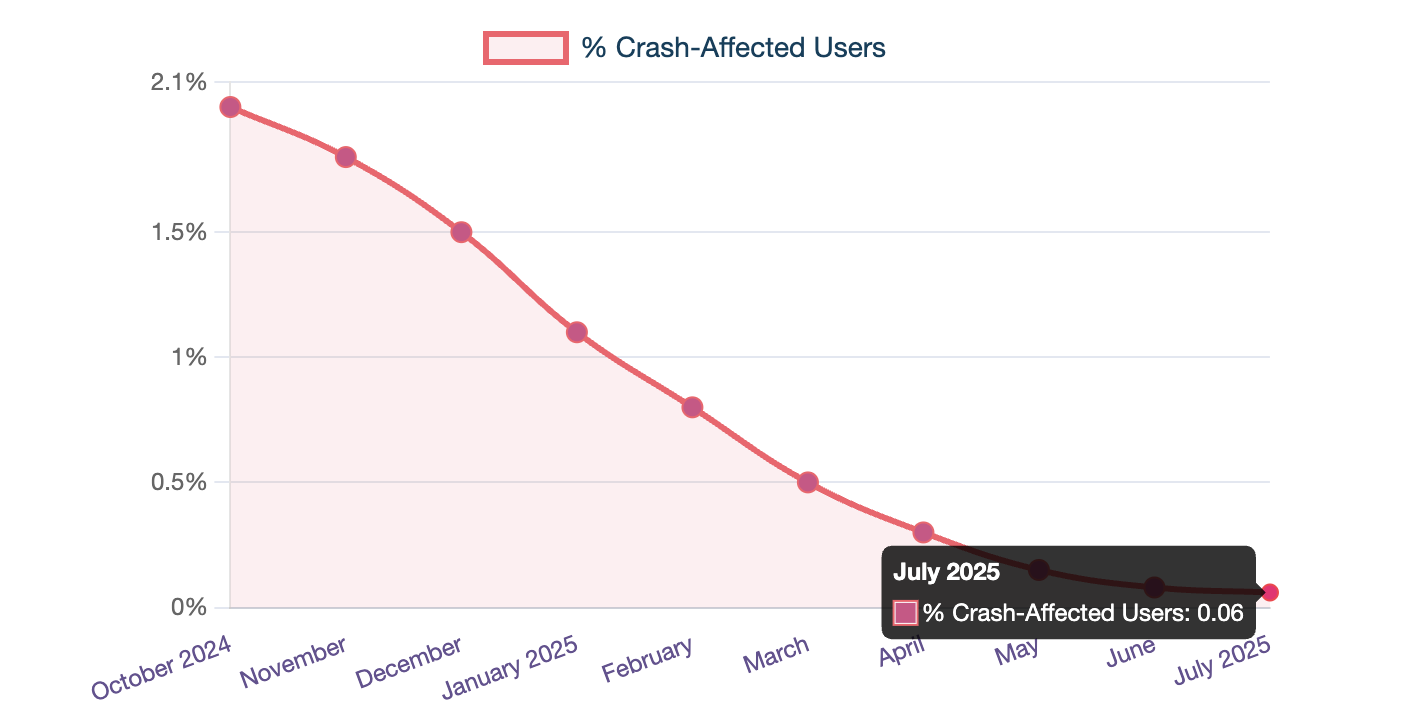
At Simpl, we've learned that mobile app stability isn't just an engineering metric—it's a direct driver of user trust and business outcomes. Here's how our small mobile team systematically reduced crashes from affecting 2% of users to just 0.06%, and the lessons that any mobile team can apply.
📍 The Wake-Up Call
October 2024 was a turning point for our mobile team at Simpl. Our Simpl mobile app, serving ~2.5M monthly users with 300K daily active users, was experiencing a stability crisis that demanded immediate attention.
The numbers were concerning:
- Around 2% of our user base was experiencing crashes. With our scale, this translates to approximately 50,000 users facing interrupted experiences.
- Critical flows were failing, directly impacting user trust and revenue.
- The crash rate was increasing as we shipped more features, revealing gaps in our monitoring and tracking systems.
Crashes directly impact trust and retention, which are critical for a financial product. Instead of waiting for complaints to escalate or metrics to dip, we made crash‑free users a first‑class product KPI, measured and acted on every single week.
🛠 Our Approach: Tools, Process, and Ownership
Our approach to solving this challenge was multi-dimensional, focusing on comprehensive monitoring, systematic processes, and proactive engineering practices. To move from scattered fixes to consistent improvement, we built a lightweight yet disciplined process:

✅ 1. Comprehensive Monitoring with the Right Tools
We use a dual-tool approach that covers our entire React Native stack:
Crashlytics handles our native crashes (Java/Kotlin on Android, Objective-C/Swift on iOS). It's particularly effective for:
- Native module crashes
- Memory-related issues
- Platform-specific problems
Sentry manages our React Native/JavaScript-level crashes, giving us visibility into:
- JS errors and exceptions
- Redux state issues
- Bridge communication problems
Both tools are integrated with our JIRA workflow, allowing us to create tickets directly from crash reports and maintain traceability from detection to resolution.
📅 2. Weekly Crash Review: Our Stability Heartbeat
Every week, our mobile engineering team gathers for a focused 1-hour crash review meeting. This isn't just a status update – it's our primary mechanism for maintaining stability and discipline.
- We track:
- New crashes, recurring issues, regressions
- Crashes introduced by new features
- Action items are logged in a Google Sheet: crash details, assignee, active versions, crash counts, crash-free users/sessions, and linked Jira tickets.
- Tickets are created directly from Crashlytics and Sentry.
- Plan crash fixes for the upcoming weekly release.
🚀 3. Release Engineering and On-Call Rotation
Our release engineer rotation is crucial to maintaining our stability standards. Each week, one team member takes on-call responsibility for:
Release Monitoring:
- Monitoring both Crashlytics and Sentry during rollouts
- Driving the weekly crash review meeting
- Updating our tracking data
- Coordinating hotfixes when needed
Staged Rollout Strategy: We use a cautious approach: 5% → 100% over a week, giving us time to catch issues before they impact our entire user base.
Hotfix Criteria: If a crash affects more than two-digit users, we immediately:
- Investigate and fix the issue.
- Release a hotfix
- Monitor the fix effectiveness
Less critical crashes get pipelined to the next weekly release.
📦 4. Version Management: Keeping the Ecosystem Healthy
We maintain only the last 4-5 versions as "stable" versions, using a combination of soft and force updates:
Soft Updates: Default approach for regular version transitions.
Force Updates: Reserved for critical scenarios:
- High-impact crashes/critical feature bugs affecting major user flows
- Security vulnerabilities
This strategy ensures we're not supporting too many versions while giving users the flexibility to update at their convenience.
🛠 5. Third-Party SDK Challenges: When Patching Becomes Necessary
While rare, we occasionally encounter crashes in third-party SDKs that we can't wait for the vendor to fix. In these cases, we:
- Create code-level patches to work around the issue.
- Share patches with the SDK maintainers via GitHub issues or pull requests.
- Maintain our patches until official fixes are released.
This approach has saved us from being blocked by external dependencies while contributing back to the open-source community.
📊 6. Data-Driven Decision-Making
We've built a comprehensive data pipeline that feeds into Databricks, giving everyone in the organisation visibility into our stability metrics.
Dashboards visualise:
- Last 30 days of crash trends
- Android vs. iOS breakdowns
- Week-over-week change in crash-free metrics
This makes data accessible beyond engineering to product and business teams.
🔔 7. Alerting and Rapid Response
We've set up multiple alert channels:
- Slack alerts for new crashes
- Email notifications for trending stability issues
- Real-time monitoring during releases
This multi-channel approach ensures that critical issues are never missed, regardless of where team members are focusing their attention.
⚙ The Technical Reality: React Native Considerations
Working with React Native adds complexity to crash management:
- Native Layer: Memory issues, platform-specific bugs, third-party SDK problems.
- JavaScript Layer: State management issues, async operation failures, bridge communication problems
Our dual-tool approach (Crashlytics + Sentry) gives us complete visibility across both layers, which is crucial for maintaining stability in a hybrid architecture.
📈 The Results
This disciplined, product-driven approach produced a measurable impact:
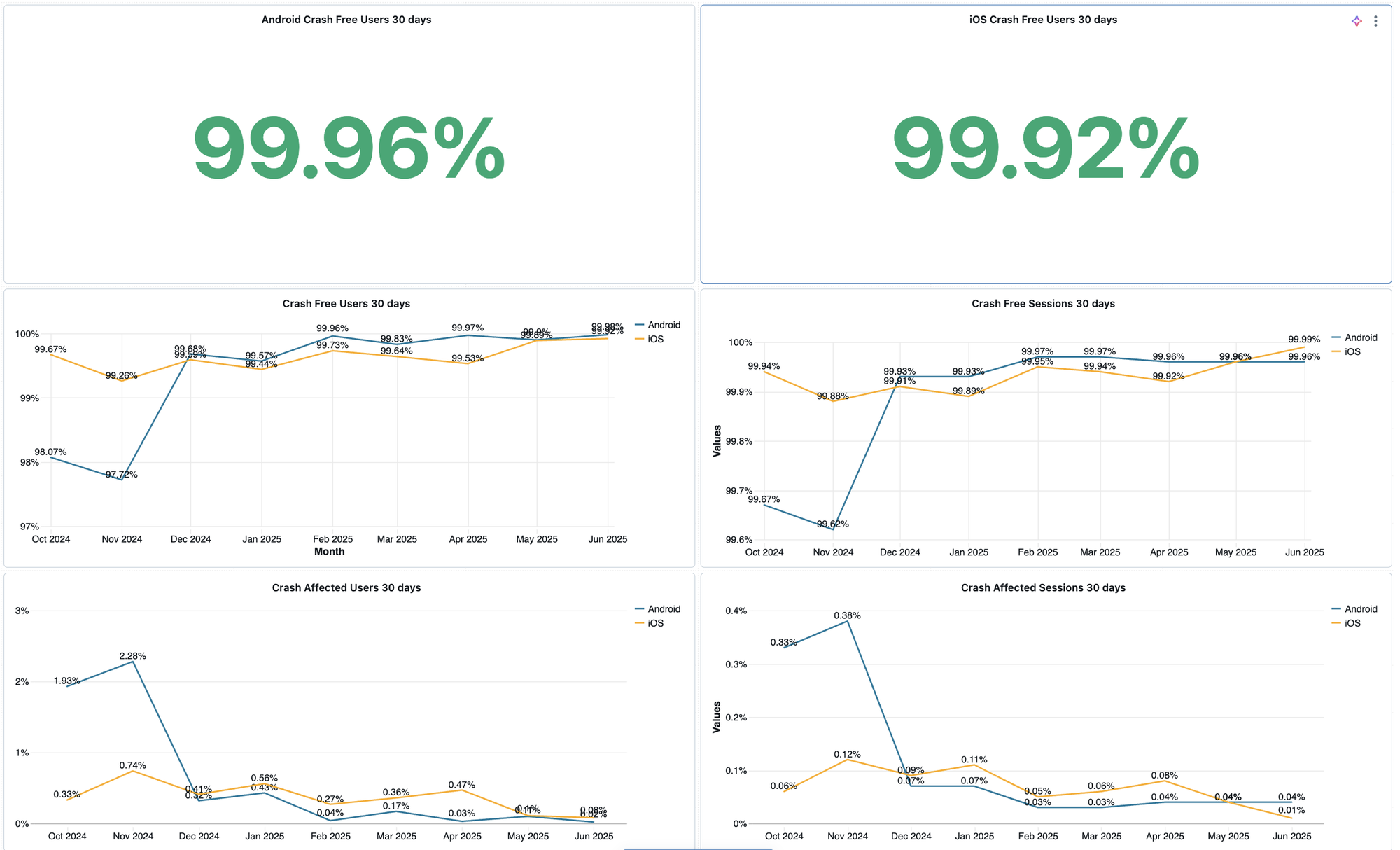
- Crash-free users improved from ~98% to ~99.94%
- Current platform breakdown: Android ~99.96%, iOS ~99.92%
- Crash-free sessions reached 99.98%.
- Over 30+ critical crashes fixed and removed from active user impact
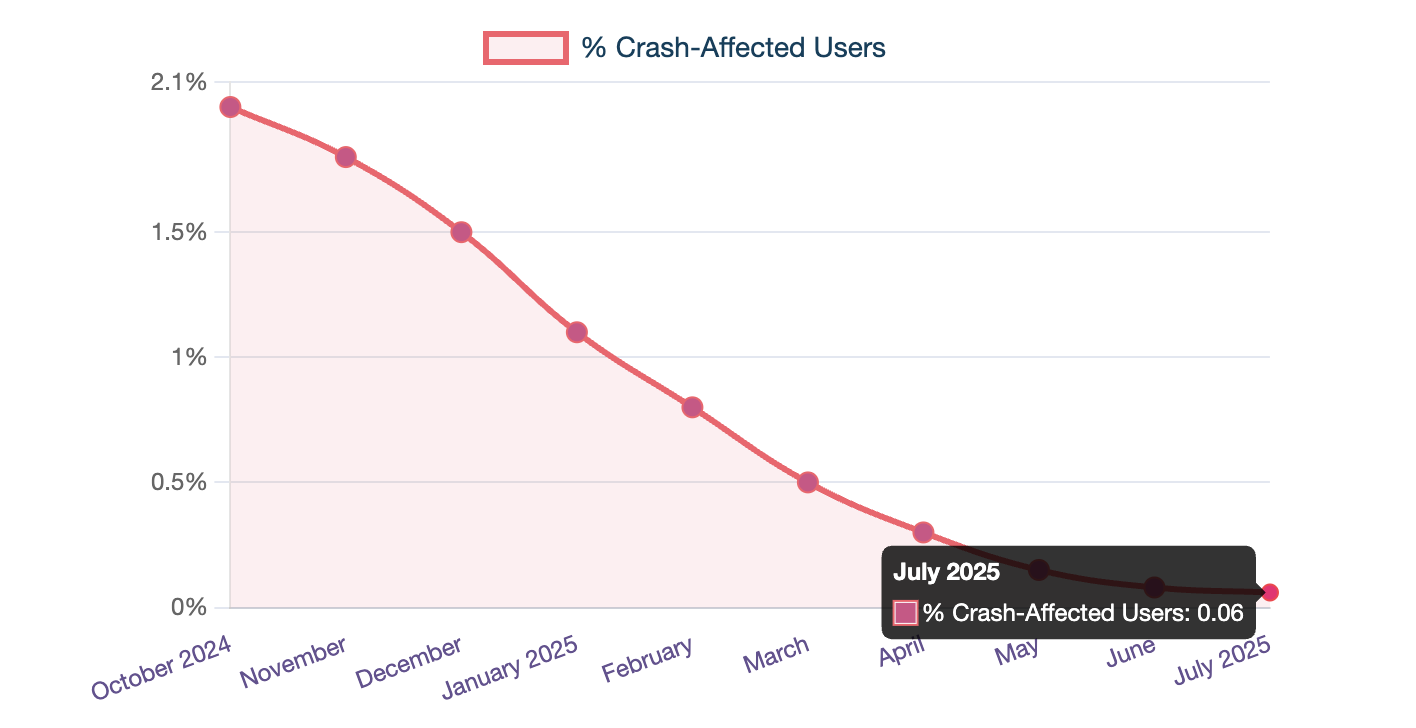
- Crash-affected users dropped from ~2% to just 0.06%.
All while maintaining a weekly app release and continuing to deliver new features.
💡 Business Impact: Why This Matters
The numbers tell a compelling story:
User Experience: Reducing crash-affected users from ~2% to 0.06% means over 50,000+ users now enjoy a smoother, uninterrupted experience each month, directly improving trust and retention.
Development Velocity: Counterintuitively, focusing on stability has made us faster. By spending less time firefighting production crashes, the team can invest more time in building and shipping features confidently.
This alignment of engineering quality with product and business outcomes shows why crash reduction isn’t just a technical initiative — it’s a strategic product investment.
✅ Key Lessons Learned
- Little Effort, Big Impact
You don’t need huge infrastructure changes to improve stability. Our approach was largely process-driven, supported by targeted tooling like Crashlytics, Sentry, and Databricks dashboards.
- Consistency Beats Perfection
Weekly crash reviews and disciplined tracking mattered more than perfect tools or frameworks. The steady rhythm of paying attention to stability every week kept standards high.
- Ownership is Critical
A dedicated release engineer on rotation ensured someone always had eyes on stability metrics, crash dashboards, and critical fixes.
- Data Visibility Drives Behaviour
Making stability data accessible to product, engineering, and business teams turned crashes from a siloed engineering concern into a shared organisational priority.
- Proactive > Reactive
Catching issues during staged rollouts — before they reach 100% of users — is far better than firefighting after deployment.
🔭 Final Thoughts
Achieving ~99.9% crash-free users wasn’t about a single big change — it was about building a culture of ownership, supported by disciplined processes and the right tools.
Every mobile team can move toward similar results by focusing on:
- Comprehensive monitoring and alerting
- Regular, structured crash reviews
- Proactive release management (including staged rollouts and hotfixes)
- Data-driven decision-making is accessible across teams.
For us, the payoff has been clear:
- A smoother, more reliable app for 2.5 million monthly users
- Fewer drop-offs and support tickets
- More focused engineering time spent building, not firefighting
Ultimately, investing in stability is about investing in user trust and product quality, and that’s something worth celebrating.