

In this article, We’ll explain the significance of control sets and the impact they generate when working with intelligence systems in a company. We will use examples from Simpl, a BNPL (Buy Now Pay Later) service, to illustrate their role in real-world applications.
Control sets are often overlooked, but they are crucial to measuring the true performance of data science models in production. Without them, organizations risk confusing correlation with causation, misjudging system impact, or making decisions based on incomplete information.
What is a Control Set?
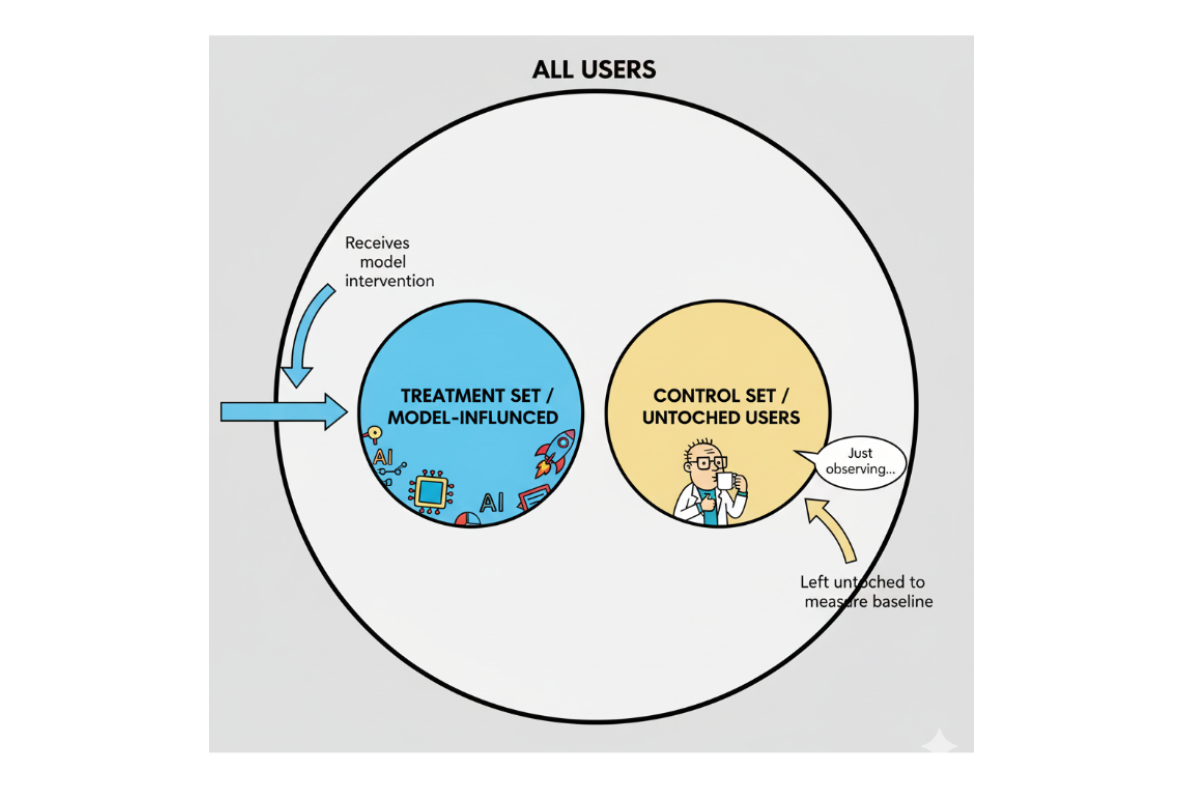
A control set is a portion of users or data that is kept free from any treatment while all other parameters remain identical to the test set. This allows teams to measure the actual effect of a treatment and understand whether observed changes are due to causation or merely correlation.
Control sets help to:
- Evaluate models in an unbiased environment.
- Understand system behavior deeply.
- Measure the long-term impact of interventions.
Formally, if ftreatment represents the outcome under intervention and fcontrol represents the baseline outcome, then the difference ftreatment - fcontrol isolates the causal lift:
Impact = f(treatment) - f(control)
By keeping a portion of the population untouched, control sets provide a baseline, enabling teams to measure the true causal effect of any model, intervention, or strategy.
🧠 Why Control Sets Matter in FinTech (The Simpl Story)
Let’s take the example of Simpl, a BNPL (Buy Now Pay Later) service that thrives on AI-driven decisions. Control sets here aren’t just a statistical curiosity- they’re a sanity check for every model we ship.
Understanding the User Lifecycle at Simpl
In order to understand the importance of control sets, first let's look at the user's lifecycle at Simpl. This context will help illustrate how control sets are put to use and why they are critical for measuring the true impact of intelligence systems.
- Underwriting: Users can use Simpl only if they are successfully underwritten. So, the first step is to evaluate users for credit worthiness using limited merchant-provided data, without requiring eKYC or mandates. A low credit limit is assigned via ML models.
- Credit Upgrade / Re-underwriting: As users transact, more behavioral and transactional data is collected. Re-underwriting then takes place - essentially providing the user with a higher credit limit while keeping risk in check using ML/DL models.
- Fraud Detection: The Anti-Fraud System (AFS) operates in parallel with the underwriting models. This vertical identifies suspicious transactions or users and takes the required steps to mitigate fraud losses. For instance, if the AFS system flags a user as fraudulent, the user may be immediately blocked from further transactions.
- Churn Prevention: The churn prevention models identify users at risk of leaving and trigger interventions to retain them. These interventions could include targeted cashbacks, personalized notifications, or even resolving underlying issues that might cause user dissatisfaction.
- Collections: If a user fails to repay the amount within the due date, the system automatically initiates reminders through messages, IVR calls, or manual follow-ups. Reinforcement Learning algorithms recommend optimal collection actions - choosing the best communication channel and timing - to maximize recovery while minimizing operational cost.
At every stage, control sets allow us to understand the real-world impact of these interventions, answer “what-if” questions, and quantify ROI accurately.
Role of Control Sets Across Verticals
1️⃣ Underwriting
In this vertical, we decide which users should receive a Simpl credit line. Only underwritten users can transact using Simpl. The underwriting process is driven by ML/DL models trained on users who have already been approved and transacted before. The objective of the underwriting process is to provide credit lines to as many people as possible while keeping delinquency rates small.
However, this setup leaves some key questions unanswered:
- What is the true delinquency rate of the overall user universe if approvals were random and not model-driven?
- What would retention and Average Order Value (AOV) be without underwriting intelligence?
- When a new model is introduced - trained on previously approved users - how will it perform on the broader, unseen universe?
Since each model learns only from already-approved users, it carries selection bias, limiting our ability to measure real-world impact.
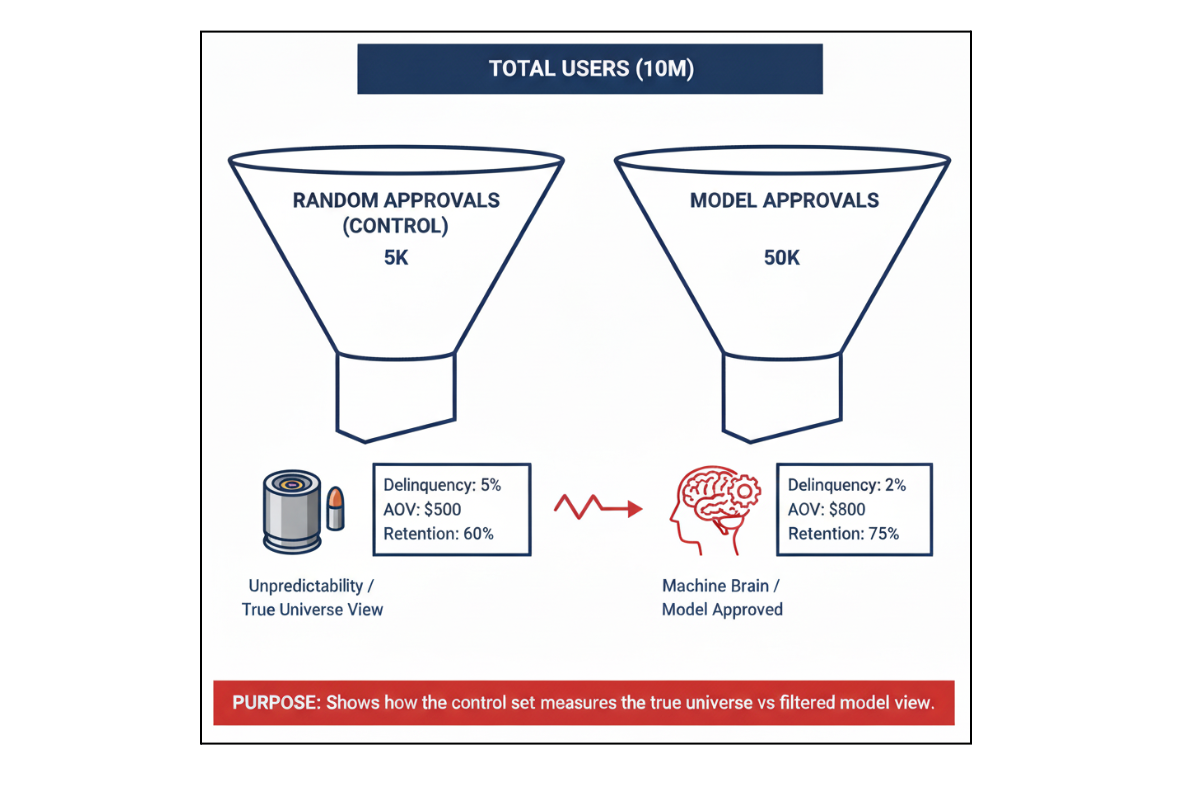
Control Set Approach
To answer these questions, we maintain a small, statistically significant control set of users who are approved randomly, independent of any model’s decision. By tracking their delinquency, retention, and AOV, we capture the true behavior of the user universe.
This provides a reliable baseline:
- The delinquency rate in this set represents the natural default rate without intelligence.
- Comparing model-approved users against this group quantifies how much delinquency, AOV, and retention have improved due to data science interventions.
- When a new model is launched, its performance on this control set shows true causal improvement, not just incremental gains on a filtered population.
Comparing model-approved users against this baseline allows us to measure real lift:
$Delinquency Reduction = (\frac{D_{control} - D_{model}}{D_{control}})$ $AOV Lift = (\frac{AOV_{model} - AOV_{control}}{AOV_{control}})$
Why It Matters
Approving users randomly is indeed risky and costly, but this controlled risk is essential to deeply understand both the model’s effectiveness and the universe’s behavior. Without it, we risk evaluating models in a biased loop.
The control set helps break selection bias and ensures we measure causation, not correlation, giving a deterministic view of underwriting performance in production.
2️⃣ Anti-Fraud System (AFS)
Trust us - We’ve answered countless “why” and “how” questions from our leadership only because the control set existed. It’s what gives us clarity amid the uncertainty of fraud detection.
At Simpl, the fraud detection system is a complex blend of LSTM models for sequential transaction behavior, GraphSAGE for network-based risk, user embeddings that capture latent behavioral patterns, and a LightGBM ensemble that integrates these signals to flag suspicious users and transactions.
Once flagged, a user is either blocked or has their credit limit downgraded. Like any other data science model, this system operates at a certain precision - which means false positives (FPs) are inevitable. Unfortunately, FPs directly impact user experience: a genuine user might get blocked or see their limit reduced without reason.
And in India, users talk far more about bad experiences than good ones - especially on social media. So naturally, leadership often wants to know:
- Are we blocking too many genuine users?
- What’s the trade-off between fraud prevention and user experience?
- What would our losses look like if we didn’t take any of these actions?
Answering these questions is difficult because once a user is blocked, their natural behavior changes. They can not transact anymore, and some even settle early out of fear - thinking Simpl might have found something serious. This biases the observed precision and makes real-world measurement unreliable.
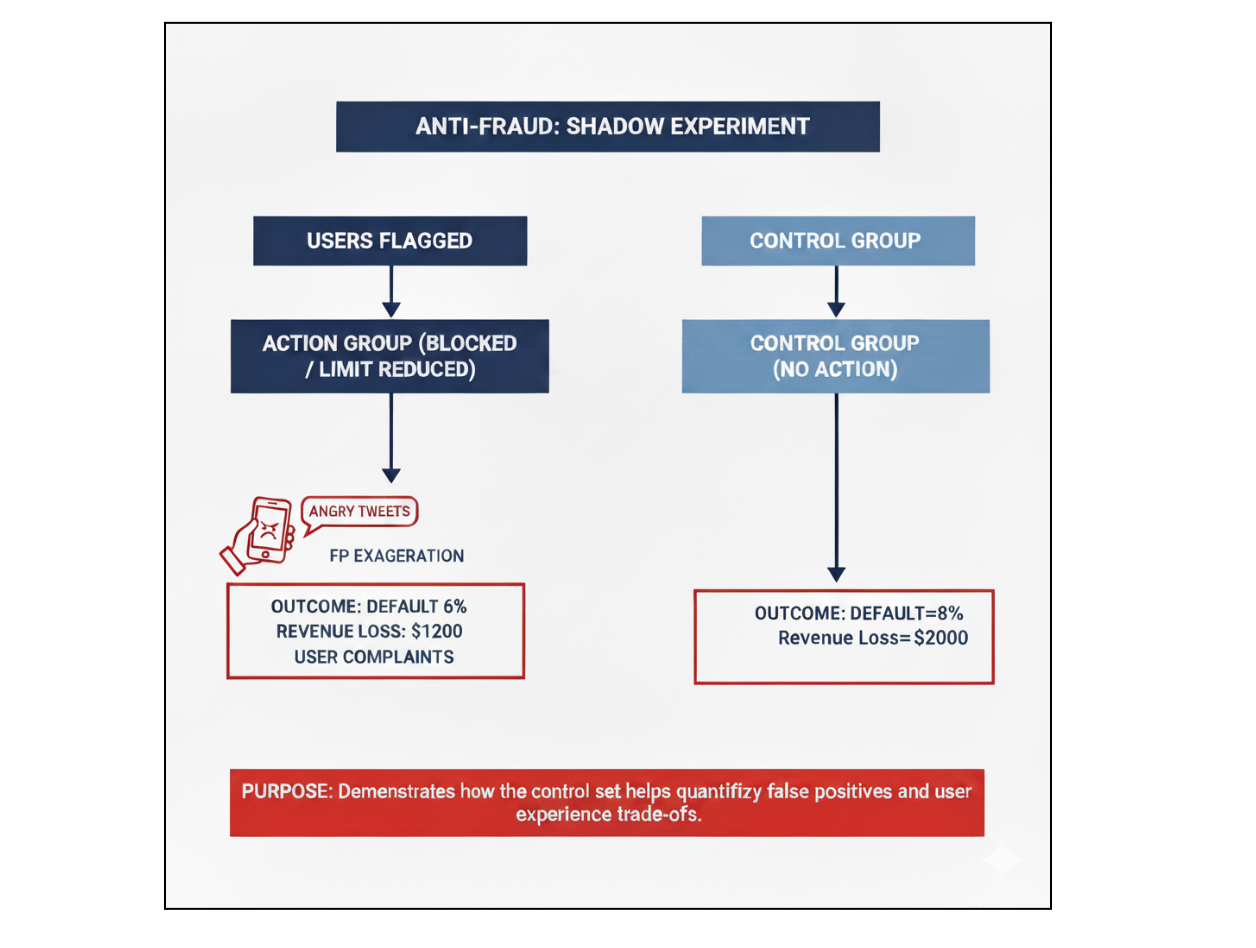
Control Set Approach
This is where the control set becomes invaluable. In the control set, we flag users as suspicious but don’t take any action - no blocking or limit downgrade. This allows us to:
- Measure the true default rate among flagged users.
- Estimate how much money would be lost if no fraud intelligence existed.
- Quantify the revenue trade-off between aggressive fraud prevention and customer experience.
In short, the control set acts as a “parallel universe” where we can see what would have happened without interference. We can quantify the impact with simple metrics:
$\text{Revenue Impact} = Revenue_{control} - Revenue_{intervention}$
$\text{Fraud Prevented} = Default_{control} - Default_{intervention}$
Examples and Practical Use
- When a Growth PM asks, “Can we NOT block users based on this new heuristic?”, instead of running a risky live experiment, we first do a dry run on the control set. This tells us directionally whether the heuristic makes sense before spending months testing it.
- If someone proposes replacing blocking with credit downgrades for all flagged users, we can simulate this on the control set across six months of data - projecting the expected revenue uplift versus fraud loss without impacting real users.
These insights save months of experimentation, reduce uncertainty, and ensure our decisions are data-driven and explainable, rather than based on gut feel that could trigger angry tweets.
Ultimately, the control set transforms how we justify actions to leadership. Instead of debating based on intuition, we can say with confidence:
“Here’s the quantified trade-off between risk, revenue, and user experience.”
3️⃣ Churn Prevention
Retention is a pressing challenge in highly competitive BNPL markets. Companies often deploy interventions - cashbacks, discounts, or notifications - targeted at users flagged by intelligence models. However, measuring impact without a control set can be misleading:
- Is the model truly identifying at-risk users, or are incentives like cashbacks temporarily keeping users around?
- How does retention in one month affect behavior in subsequent months?
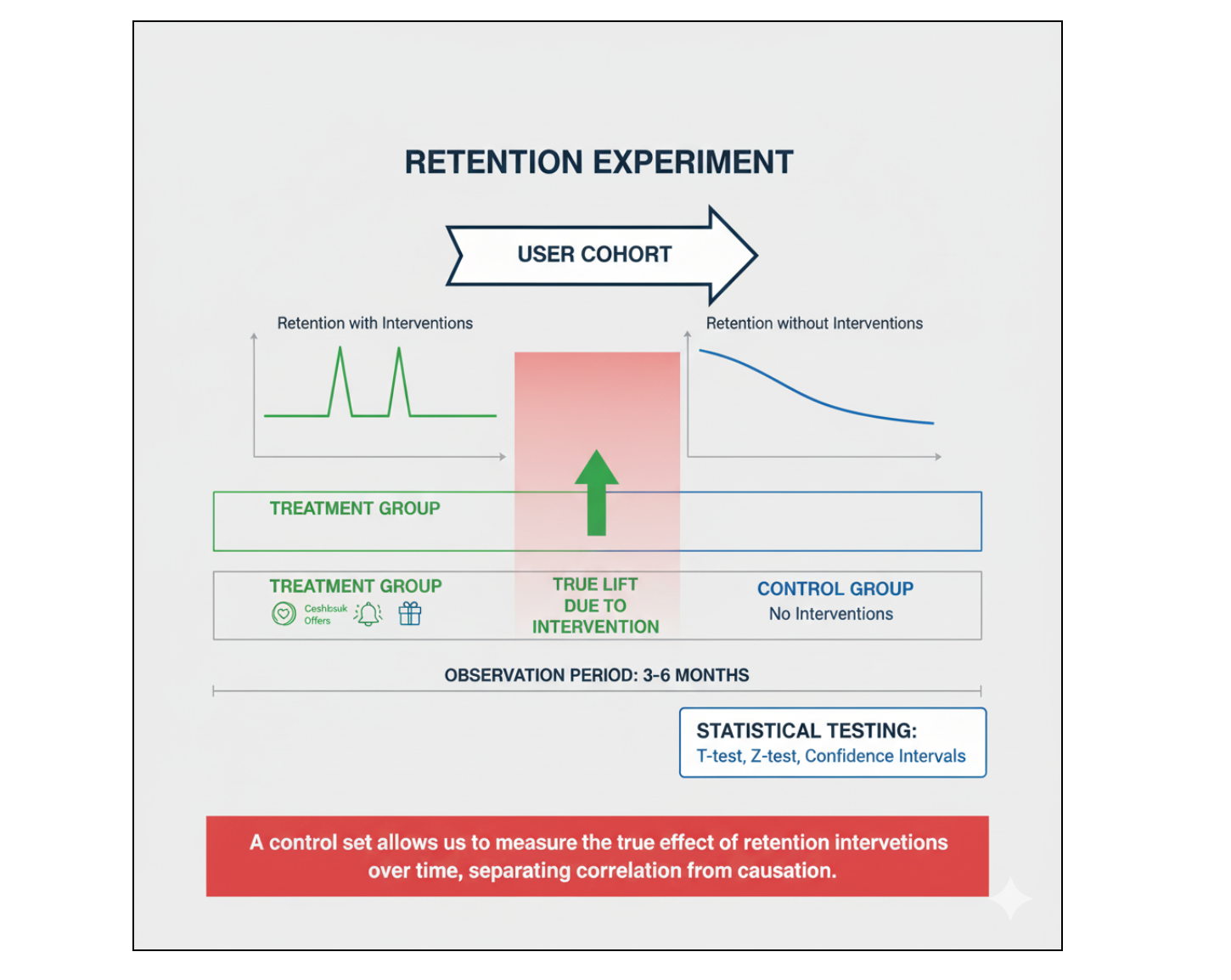
Control Set Approach
To answer these questions, a small portion of users flagged for churn prevention is deliberately left untreated. These users form the control set, allowing us to observe their natural churn patterns over several months. This approach captures both immediate and delayed effects, as well as ripple effects across the system.
Example: A user may stay for one month due to a cashback incentive but churn in the following month. In businesses operating at thin margins, such short-term retention could result in negative ROI despite apparent gains in the test set. Comparing the control set with treated users isolates the true causal effect of interventions, helping quantify long-term value.
Formally, if we denote retention at month t as Rt, the control set allows us to calculate the net lift of an intervention:
$Net Lift = \sum_{t=1}^{6} (R_{t}^{test} - R_{t}^{control})$
This measure captures the incremental retention directly attributable to our interventions, stripping away the noise of natural user behavior. Importantly, it also reveals the ripple effects: users who appear “retained” in the short term might churn later, or incentives might shift behavior in unexpected ways. Understanding these dynamics helps leadership make data-backed decisions that balance short-term retention with long-term profitability, rather than relying on surface-level improvements in monthly metrics.
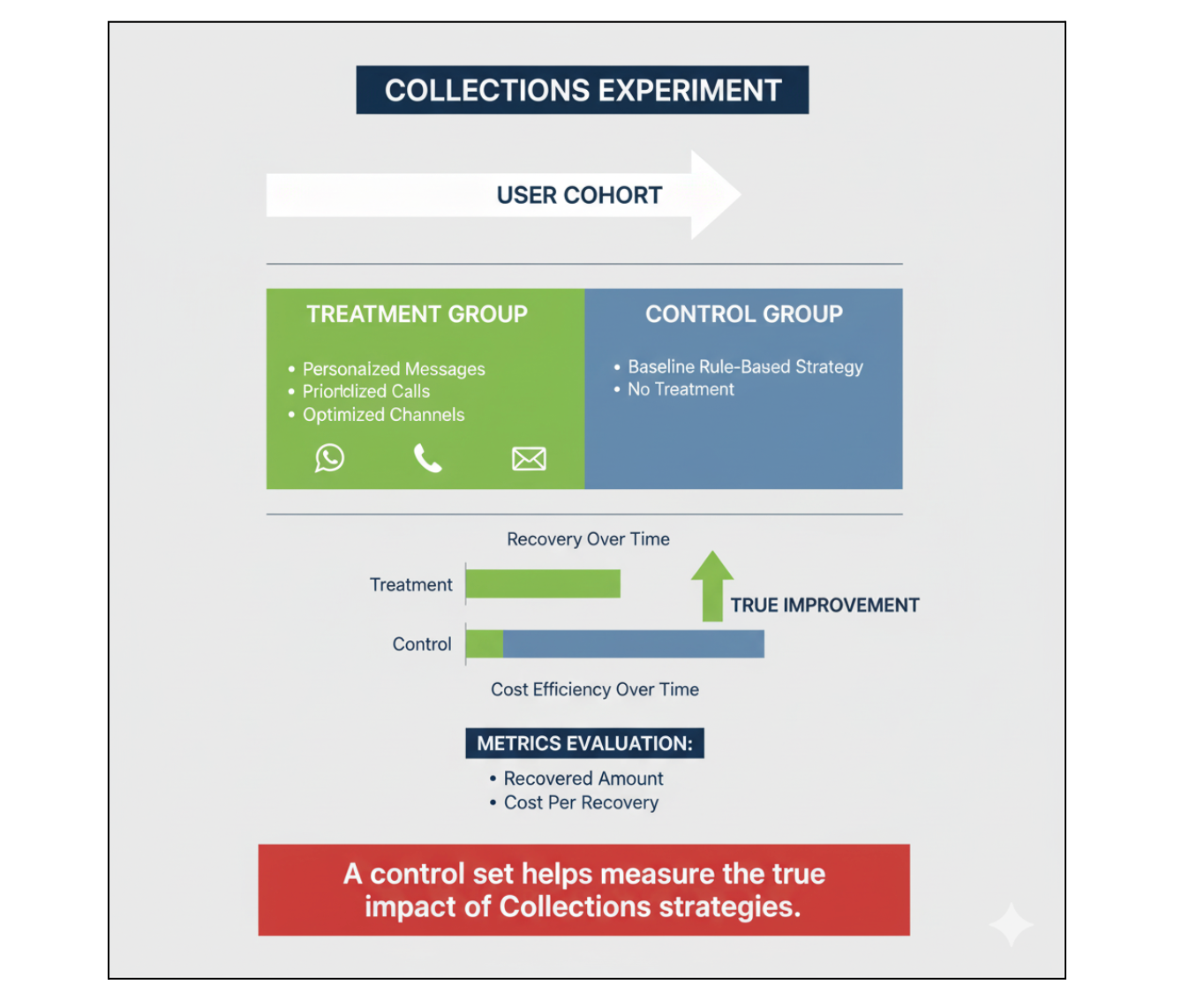
4️⃣ Collections
At Simpl, customers are expected to settle their payments within the due date. If they don’t, the collections process kicks in - starting with reminders via messages, push notifications, and WhatsApp, and later moving to calls. The goal is clear: recover as much money as possible, as quickly as possible, and at minimal cost.
Before Data Science interventions:
- Uniform reminders were sent to all users across channels.
- Calls were initiated on a fixed schedule starting on D7 (seven days after bill generation).
- Collections followed a one-size-fits-all approach.
After implementing the Collection Intelligence Framework (CIF):
- Messaging and call sequences are personalized for each user.
- Channels and timings are optimized to maximize effectiveness.
- Risk-based prioritization is applied using Reinforcement Learning algorithms, ensuring high-risk users are targeted efficiently.
Control Set Approach
To measure the true impact of CIF, we maintain a control set of users under the old rule-based system - effectively untreated. This allows us to understand:
- How much money would have been collected without any intervention (baseline).
- The improvements in recovery rate and efficiency introduced by CIF.
- Cost savings from optimized collection strategies.
Measuring Impact
The control set allows us to quantify key metrics clearly:
$Incremental Lift = (Recovery_{CIF} - Recovery_{control})$
We also compute cost efficiency:
$Cost Per Rupee Collected = \frac{Total\ Cost\ of\ Intervention}{Total\ Amount\ Collected}$
By comparing treated users with the control set, we can quantify not only revenue uplift but also operational efficiency gains. For example, analyzing six months of data reveals:
- The incremental recovery achieved through personalized interventions.
- Reduction in cost per recovered user thanks to optimized messaging and call schedules.
- Long-term efficiency improvements without compromising portfolio health.
Control sets make it possible to evaluate collections strategies rigorously, providing clarity on the real value of ML-driven decisions and ensuring management can make data-backed choices rather than relying on assumptions or intuition.
Creating an Effective Control Set
Key Principles for Creating Control Sets
- Deterministic Assignment: A control set must be deterministic - once a user is assigned to the control set, they should remain there consistently throughout the experiment. This ensures that long-term or delayed effects can be accurately measured.
Example: In the Anti-Fraud System (AFS), if a user is flagged and falls into the control set in March, we need to observe their behavior over subsequent months. If the same user moves in and out of control and test sets, we cannot accurately measure delayed defaults or the true impact of interventions. Similarly, in Churn Prevention, users assigned to a control set should remain there for at least 4–6 months to capture ripple effects on retention.
- Separation Across Systems: Control sets in one vertical must remain independent of other verticals to avoid bias.
Example: Users in the AFS Control set may overlap with Churn Control or Collections Control cohorts; but this overlap should not be selectively enforced or avoided, as doing so could distort results and compromise the validity of vertical-specific insights.
Implementation Tip: One practical approach is using a deterministic hashing function (e.g., SHA-256) to assign users consistently:
Deterministic SHA hashing approach:
import hashlib
def split_test_variation(key, test_name, nvariations):
"""
Returns a deterministic randomized variable based solely on the key and test_name.
"""
m = hashlib.sha256()
m.update(key.encode("utf-8"))
m.update(test_name.encode("utf-8"))
return int(m.hexdigest()[:8], 16) % nvariations
This ensures consistent control set assignment while keeping verticals independent.
Conclusion
Control sets are indispensable for understanding the real impact of data science interventions. They allow teams to:
- Measure causation versus correlation
- Evaluate model performance in unbiased environments
- Optimize interventions across underwriting, fraud, churn, and collections
By thoughtfully maintaining control sets, organizations like Simpl can:
- Validate the effectiveness of intelligence systems
- Develop deep operational understanding
- Make smarter, data-driven decisions with controlled risk
A well-designed control set is more than a too -it is the backbone of scientific decision-making in AI-driven businesses.
“Every great data story deserves a skeptic, and that skeptic is your control set.”