
In the world of relational databases, data integrity is paramount. To guarantee reliable processing of transactions, databases adhere to the ACID principles. Each principle plays a crucial role:
- Atomicity ensures transactions are all-or-nothing.
- Consistency guarantees valid states before and after transactions.
- Isolation prevents concurrent transactions from interfering with each other.
- Durability ensures that once a transaction is committed, it remains so, even in the face of system failures.
Database designers have developed the concept of "Isolation level". Various isolation levels provide a different tradeoff between application perceived anomalies and performance. There are four prominent isolation levels that have been developed by ANSI.
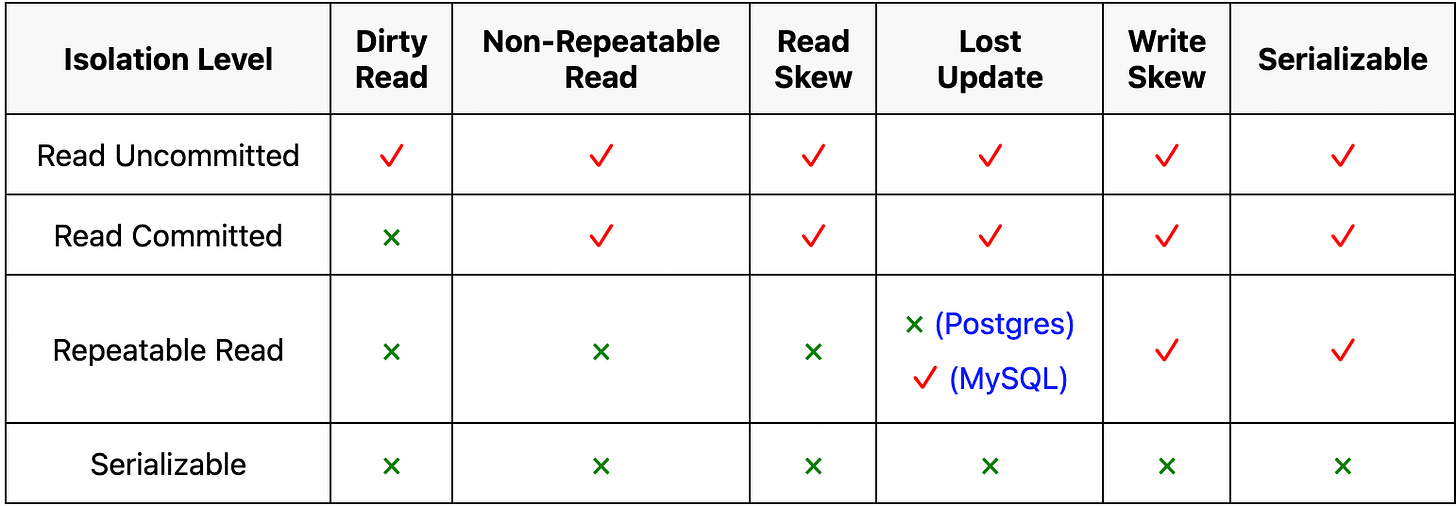
In this article, we will explore each isolation level in detail, understand the types of issues and anomalies that can occur at each level—such as dirty reads, non-repeatable reads, phantom reads, and write skew—and see how each successive isolation level addresses the shortcomings of the previous one, providing stronger guarantees and stricter data consistency as we move up the levels.
What is Transaction Isolation?
Isolation in the sense of ACID means that concurrently executing transactions are isolated from each other: they cannot step on each other’s toes.
Isolation is particularly significant in multi-user environments, where multiple transactions run concurrently and work on the same database records. It governs how and when changes made by one transaction become visible to others, striking a delicate balance between data correctness and system performance. Understanding the various Transaction Isolation Levels helps developers design reliable and efficient applications under concurrent workloads.
The ANSI SQL standards define four key transaction isolation levels to manage the behavior of concurrently executing transactions:
- Read Uncommitted
- Read Committed
- Repeatable Read (Snapshot Isolation)
- Serializable
Why do we have different isolation levels?
Each isolation level offers a different balance between concurrency and consistency. As we move from weaker to stronger isolation, more potential anomalies are prevented, but system concurrency and throughput may decrease.
Over time, academic research has uncovered various concurrency anomalies. Each time a new issue is identified, the ANSI SQL standards evolve to define a new isolation level to address it.
It would be tough for application developers to identify these concurrency issues at runtime. Instead, these tools are provided as a solution so developers can pick any isolation level based on the expected performance and transaction isolation guarantee needed by the application.
Read Uncommitted Isolation Level
The Read Uncommitted level is the weakest among all isolation levels. At this level, transactions can read changes made by other transactions before they are committed. This allows access to uncommitted (temporary) data, which can lead to a dirty read.
This isolation level is not supported by most SQL servers, including MySQL, PostgreSQL, MariaDB, or SQLite.
Dirty Read Anomaly
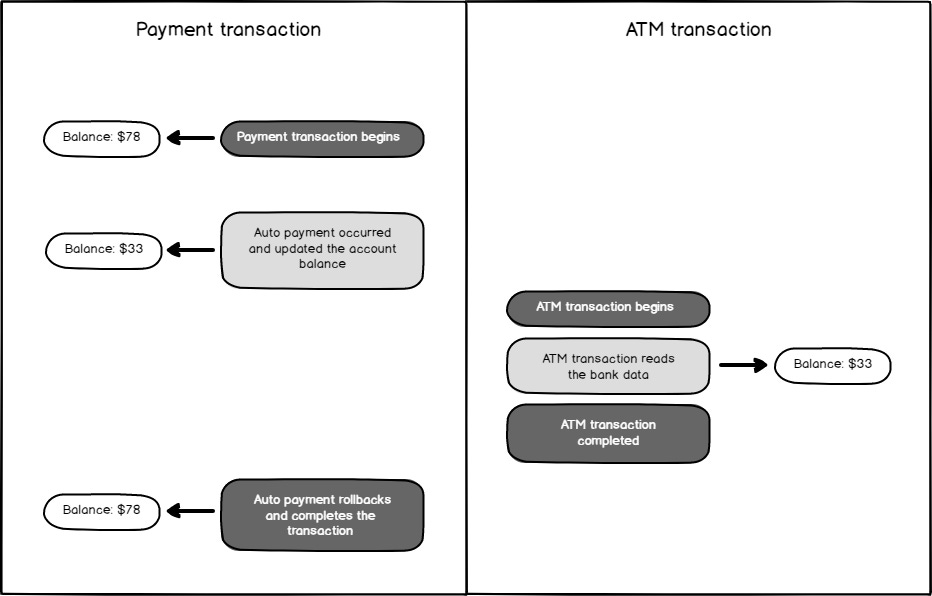
Let us assume a banking system: a database transaction attempts to perform an auto-debit of $45, modifying a person's account balance from $78 to $33. Before this transaction completes, the ATM transaction begins and reads the balance as $33, a value that has not been committed yet. Shortly after, the payment transaction rolls back, restoring the actual balance to $78.
However, the ATM transaction has already been completed based on the uncommitted and ultimately invalid data. This is a classic example of a dirty read, where one transaction reads changes made by another transaction that were never finalized. Dirty reads can lead to incorrect application behavior and are prevented by isolation levels Read Committed and above.
{kind=link}
Read Committed Isolation Level
When a transaction uses this isolation level, a SELECT query (without a FOR UPDATE/SHARE clause) sees only data committed before the query began; it never sees the uncommitted data or changes committed by concurrent transactions during the query's execution.
However, SELECT does see the effects of previous updates executed within its transaction, even though they are not yet committed. Also note that two successive SELECT commands can see different data, even though they are within a single transaction, if other transactions commit changes after the first SELECT starts and before the second SELECT starts.
So if we use Read Committed as the isolation level, then the ATM Transaction to fetch the account balance would have returned the correct response of $78, as the other concurrent transaction has not yet committed its changes.
Non-Repeatable Read Anomaly
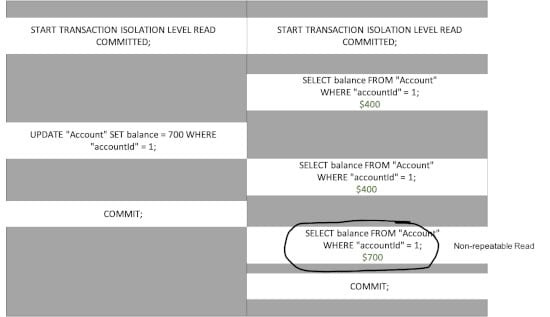
In this example, two concurrent transactions are running in the Read Committed isolation level. The transaction on the right tries to query the balance of the accountid=1 and get a response of $400. Meanwhile transaction on the left modifies the balance of accountid=1 to $700 and commits. Back on the right, when the same query is run again, the balance is now $700, even though it was $400 just moments ago.
{kind=link}
{kind=link}
Lost Updates Anomaly
Let us assume we persist a counter value in the database and provide only two operations as get count and set count. In the below case, two users are trying to increment the counter. Both User 1 and User 2 read the counter value as 42. Each user independently increments the value 42 + 1 = 43 and sets the counter to 43. User 1 writes back 43. User 2, unaware of User 1’s update, also writes back 43. As a result, one increment is lost, and the final counter is 43, not 44 as it should be.
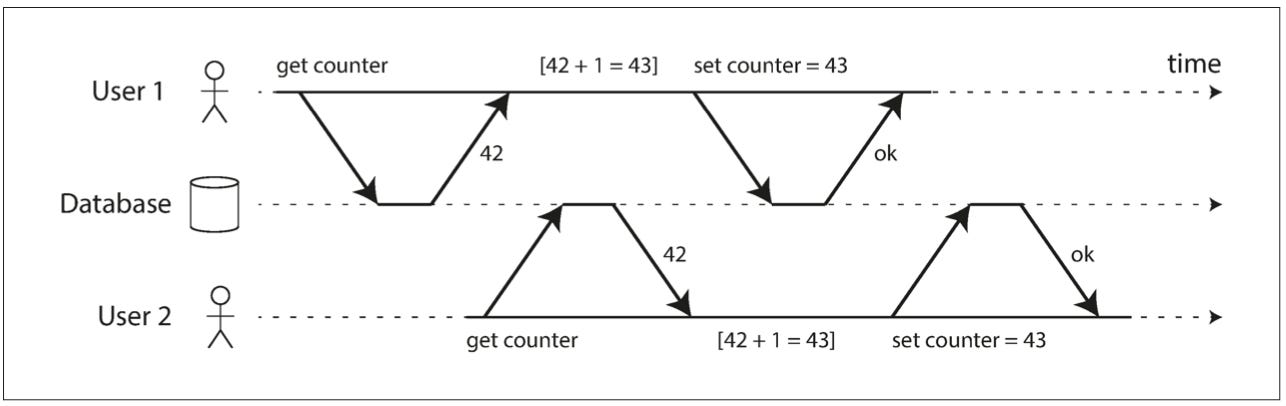
A lost update occurs when two transactions read the same data, make changes based on the same initial value, and write back their updates, but one of the updates silently overwrites the other. The database does not detect this conflict, and the result is that one transaction’s update is lost.
Read Skew Anomaly
Alice starts a transaction and first reads the balance of Account 1. She sees $500.
At the same time, a Transfer transaction begins and transfers $100 from Account 2 to Account 1. It updates Account 1 to $600. Then it deducts $100 from Account 2, reducing it to $400. Finally, it commits.
After that, Alice's transaction proceeds to read the balance of Account 2, now $400. So within the same transaction, Alice sees Account 1 = $500 (before the transfer), Account 2 = $400 (after the transfer).
This is an inconsistent snapshot, these two balances never coexisted in the real database. In fact, at no point were Account 1 and Account 2 holding $500 and $400, respectively.
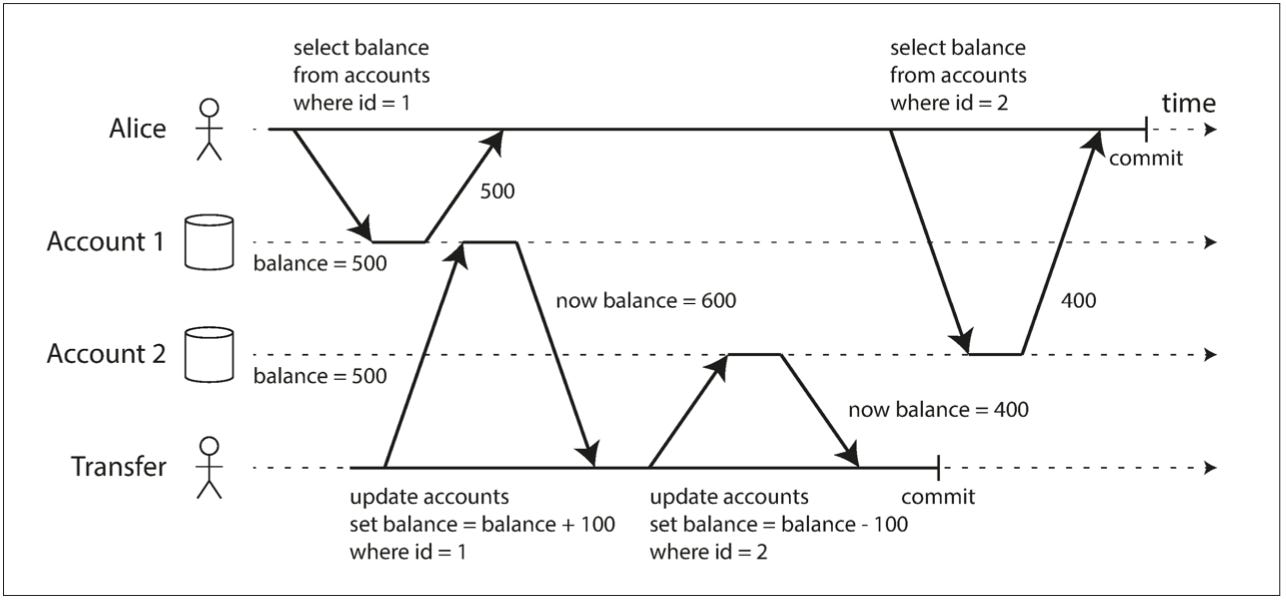
Read Skew occurs when a transaction reads related data at two different times during its execution and sees an inconsistent snapshot because another concurrent transaction modified the data in between. This can result in a view of the data that never actually existed at any single point in time.
Repeatable Read (Snapshot) Isolation Level
The Repeatable Read isolation level only sees data committed before the transaction began; it never sees either uncommitted data or changes committed by concurrent transactions during the transaction's execution. However, each query does see the effects of previous updates executed within its transaction, even though they are not yet committed.
In PostgreSQL, any concurrent updates cause the later transaction to roll back, and the application needs to retry it. This is not the case in MySQL.
Let us discuss how the Snapshot Isolation level solves the problems we discussed as part of the Read Committed isolation level.
Repeatable Read: In the example mentioned above, two reads happening inside the same database transaction get different results of $400 and $700 as the balance of the same accountID 1. But in Snapshot Isolation, every transaction operates on a private snapshot of the database taken before its first read, so both queries would return $400.
Read Skew: This would be solved similarly to that of repeatable read, the balance of Account 1 and Account 2 will be returned as $500, which is the balance before the Transfer transaction started.
Lost Updates: In the lost update example, two transactions try to read the same initial value and modify it concurrently. In the PostgreSQL database second transaction will be rolled back, and the application will need to retry it. But in the MySQL database, it silently goes through unless explicit locks are acquired.
Write Skew Anomaly
Write skew is a concurrency anomaly that occurs when two transactions read overlapping data, make decisions based on what they see, and then write changes to non-overlapping parts of the data, but the combination of their writes violates an intended invariant or business rule.
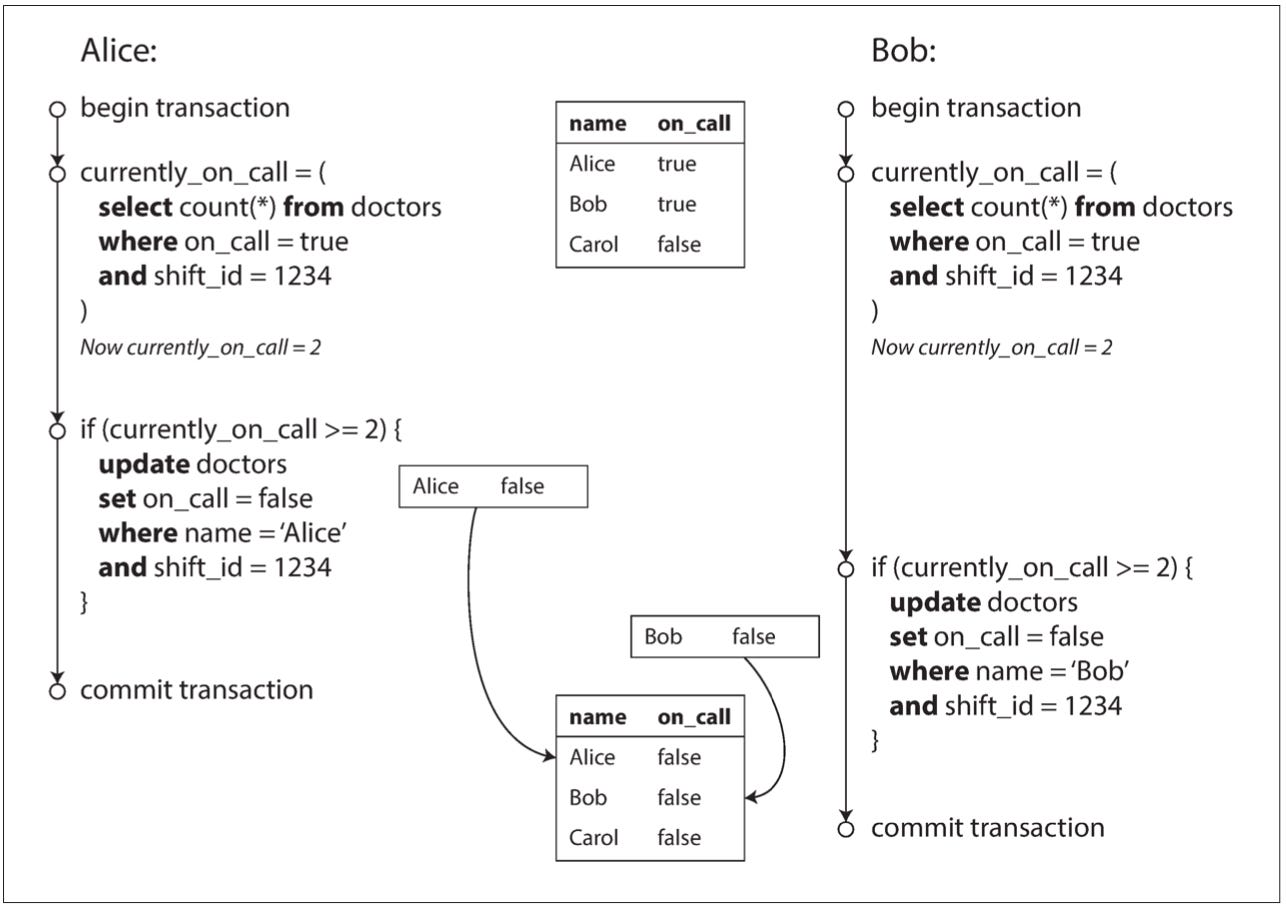
Consider the two transactions in the example below. Each checks whether there are at least two doctors on call, and if so, takes one doctor off call. Given an initial state where Alice and Bob are the only doctors on call, it can easily be verified that executing T1 and T2 sequentially in either order will leave at least one doctor on call, making these transactions an effective way of enforcing that invariant.
But running both transactions concurrently violates that invariant. Both transactions read from a snapshot taken when they start, showing both doctors on call. Seeing that, they both proceed to remove Alice and Bob, respectively, from the on-call status. Even though updates take write locks, they don’t conflict since the transactions modify disjoint rows, not overlapping ones.
Serialization Anomaly
A serialization anomaly occurs when the outcome of concurrently executing transactions is not equivalent to any serial (one-at-a-time) execution order. This violates serializability, which is the highest isolation guarantee. Even if individual transactions are logically correct, concurrent execution may lead to inconsistent or incorrect results if isolation isn’t strict enough.
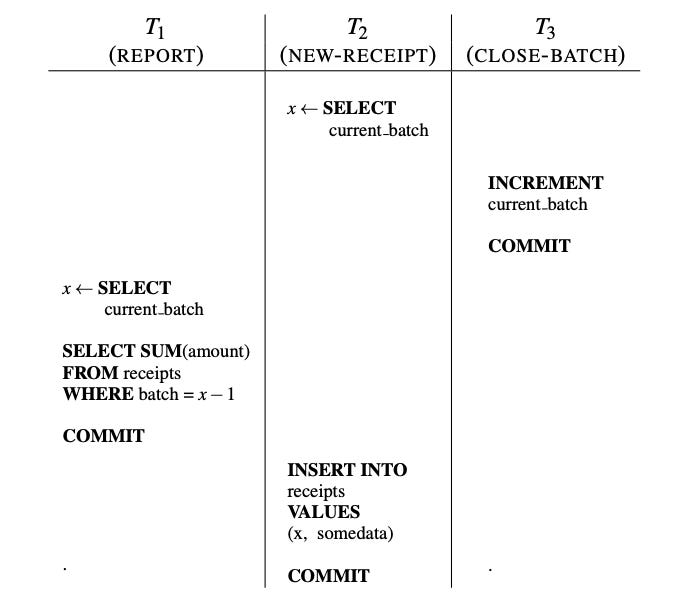
Consider a transaction-processing system that maintains two tables. A receipts table tracks the day’s receipts, with each row tagged with the associated batch number. A separate control table simply holds the current batch number. There are three transaction types:
- NEW-RECEIPT: reads the current batch number from the control table, then inserts a new entry in the receipts table tagged with that batch number
- CLOSE-BATCH: increments the current batch number in the control table
- REPORT: reads the current batch number from the control table, then reads all entries from the receipts table with the previous batch number (i.e., to display a total of the previous day’s receipts)
The following useful invariant holds under serializable executions: after a REPORT transaction has shown the total for a particular batch, subsequent transactions cannot change that total. This is because the REPORT shows the previous batch’s transactions, so it must follow a CLOSE-BATCH transaction. Every NEW-RECEIPT transaction must either precede both transactions, making it visible to the REPORT, or follow the CLOSE-BATCH transaction, in which case it will be assigned the next batch number.
However, the interleaving shown in the figure below is allowed under SI and violates this invariant. T2 uses the previous batch number because it starts before T3 commits the increment, but its insert isn’t seen by T1’s report, leading to an inconsistent view. Interestingly, this anomaly requires all three transactions, including T1, even though it is read-only. Without it, the execution is serializable, with the serial ordering being hT2, T3i. The fact that read-only transactions can be involved in SI anomalies was a surprising result.
Serializable Isolation Level
The Serializable isolation level provides the strictest transaction isolation. This level emulates serial transaction execution for all committed transactions, as if transactions had been executed one after another, serially, rather than concurrently. However, like the Repeatable Read level, applications using this level must be prepared to retry transactions due to serialization failures.
This isolation level works the same as Repeatable Read, except that the database also monitors for conflicting reads/writes and forces at least one transaction to retry, ensuring the outcome reflects some serial order.
MySQL provides serializability using strict two-phase locking (S2PL). In S2PL, transactions acquire locks on all objects they read or write, and hold those locks until the transaction commits. PostgreSQL does not use S2PL, but adds additional checks to determine whether anomalies are possible.
Let us discuss how the Serializable Isolation level solves the problems we discussed as part of the Repeatable Read Isolation level.
Write Skew: In the write skew example discussed above, two transactions run concurrently, read the same set, but update disjoint sets of data. In the Serializable isolation level, the second transaction will be rolled back by the database, because the read lock in the first transaction violates the update done in the second transaction.
Serialization Anomaly: Similar to write skew, as part of a serialization anomaly example, read-write locks violation will happen between T2 and T3, and the transaction T2 will be rolled back by the database, preventing the anomaly.
Conclusion
Understanding transaction isolation levels is crucial for building reliable and concurrent systems using relational databases. Each level—from Read Uncommitted to Serializable—represents a deliberate trade-off between performance and consistency, progressively addressing a wider range of anomalies such as dirty reads, lost updates, read skew, write skew, and serialization anomalies.
While Read Committed is sufficient for many practical scenarios, applications that enforce strict business invariants or involve sensitive data workflows may require stronger guarantees offered by Repeatable Read or Serializable isolation. Choosing the right level isn’t about always picking the strongest—it's about aligning the isolation strategy with the specific correctness requirements and performance characteristics of your application.
Ultimately, transaction isolation levels aren't just a database detail—they define the concurrency contract between your application and the database. A solid understanding of these levels enables developers to write safer, more predictable, and more scalable systems without having to handle every race condition manually.